DynaMo: Why Predict Just One Token at a Time?
DynaMo is a suite of multi-token prediction models. Our models are instantiated using the Pythia weights. Our models parallely generate multiple tokens using independent token heads.
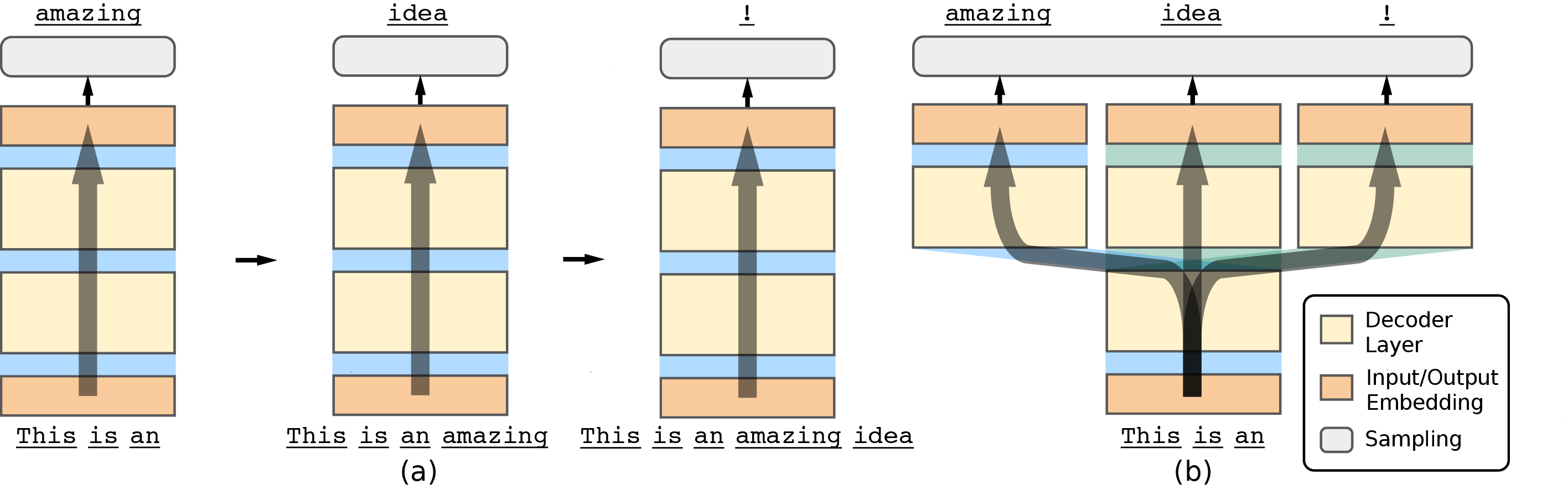
Training
We implement training using a modified CLM objective that trains each token head independently using the following loss function:
\[\mathcal{L}_{\text{T}n} = - \frac{1}{N} \sum_{j=1}^N \sum_{t=1}^{L - n + 1} \log p(\mathbf{x}_{t+n}^j|\mathbf{x}_{1:t}^j)\]for the nth token head. Here, N is the number of sequences in the training set and the length of the jth sequence is L.
Multi-token Generation
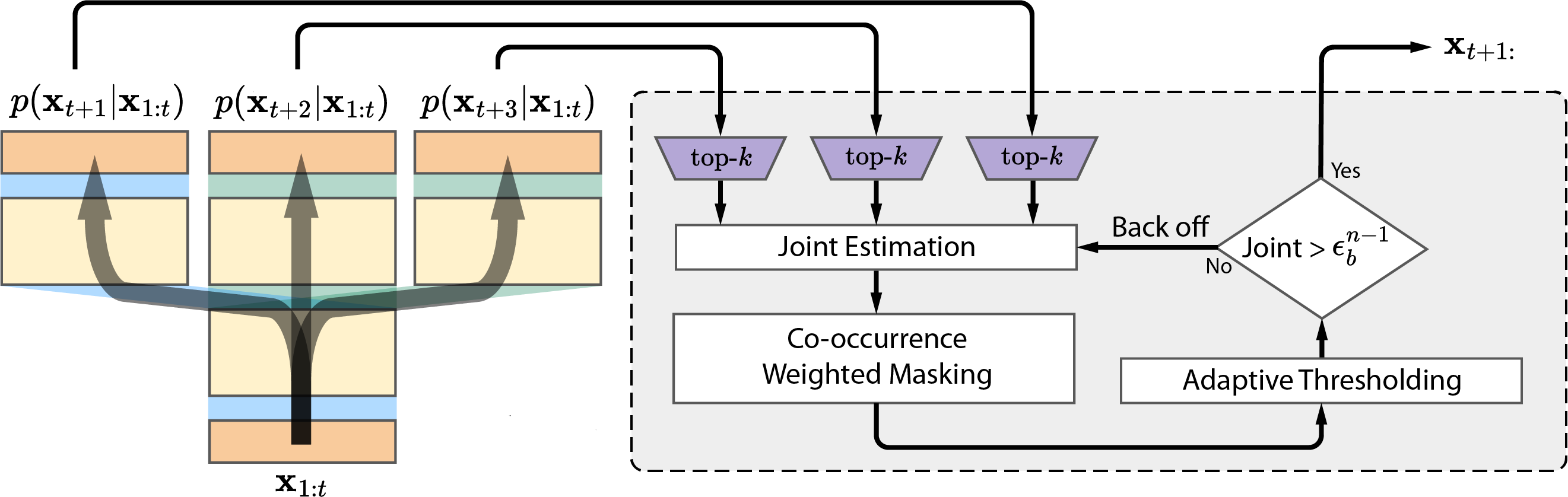
We propose three novel techniques to execute multi-token generation using the DynaMo models:
- Co-occurrence weighted masking: To fix the estimated joint probability distribution that makes the independence assumption, we apply co-occurrence weighted masking to filter out improbable token combinations.
- Adaptive thresholding: We implement adaptive thresholding of the estimated joint probability distribution to further boost performance.
- Dynamic back-off: We back-off to lower-order n-gram prediction when all the probabilities in the predicted joint probability distribution fall below a threshold.
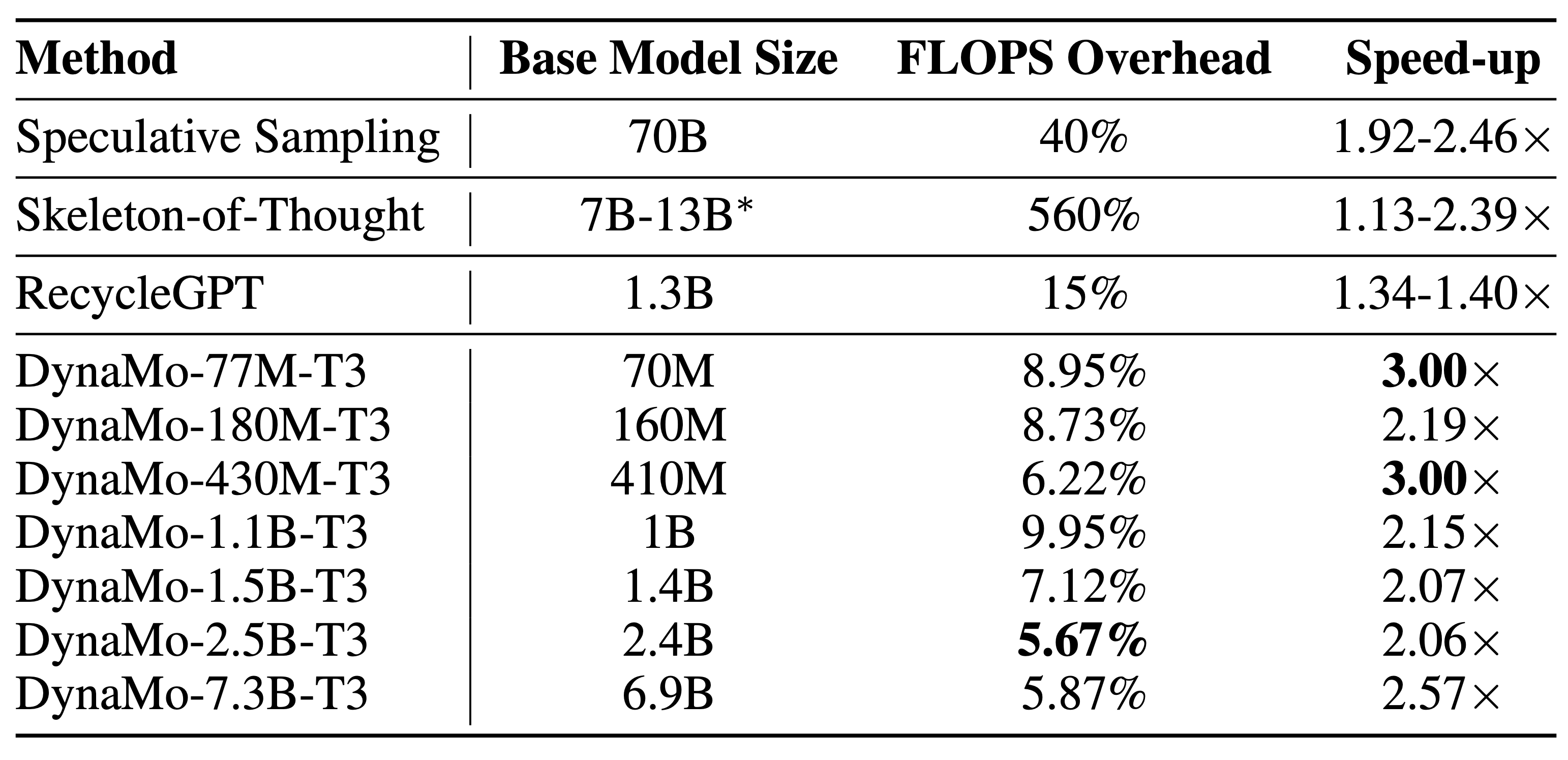
We show comparisons with other text generation methods below.
Instruction Finetuning
We finetune our models on a filtered Alpaca dataset. This gives us chat versions of our multi-token models.
Developer
Shikhar Tuli. For any questions, comments or suggestions, please reach me at stuli@princeton.edu.
License
We are working with Samsung’s legal team to publicly release the source code and model weights. We also plan to release the paper on arXiv soon. Stay tuned!